
Fast.
Secure.
Affordable.
Reclaim your Internet freedom in just a few clicks
Protect your devices from hackers with VPN

Security
Shop and pay safely on public Wi-Fi without any worries.

Privacy
Keep your online activity secure from prying eyes.

Freedom
Stream content securely wherever you are.
Get complete online protection
Securely access websites, apps, streaming platforms, and gaming sites.

Take control of your data
With FastVPN, all your Internet traffic is encrypted, protecting your private data on public Wi-Fi.

Browse the Internet anonymously
We won’t track what you search for online with our strict no-log policy.

Access worldwide content
Stream content wherever you are.
Get the best VPN price available
Save big with our wallet-friendly plans
| FastVPN | Nord VPN | Express VPN | Surfshark | |
|---|---|---|---|---|
| Monthly Plan | $0.99/mo | $12.99/mo | $12.95/mo | $12.95/mo |
| 1-Year Plan | $18.88 $1.57/mo | $59.88 $4.99/mo | $99.84 $8.32/mo | $47.88 $3.99/mo |
The details in the comparison table were correct as for August 08, 2023.
The information for each competitor may not include certain features, functionalities or quantities and is subject to change.
Choose your VPN plan
Save up to 45% 1-year plan or get a 1-month plan for only $0.99

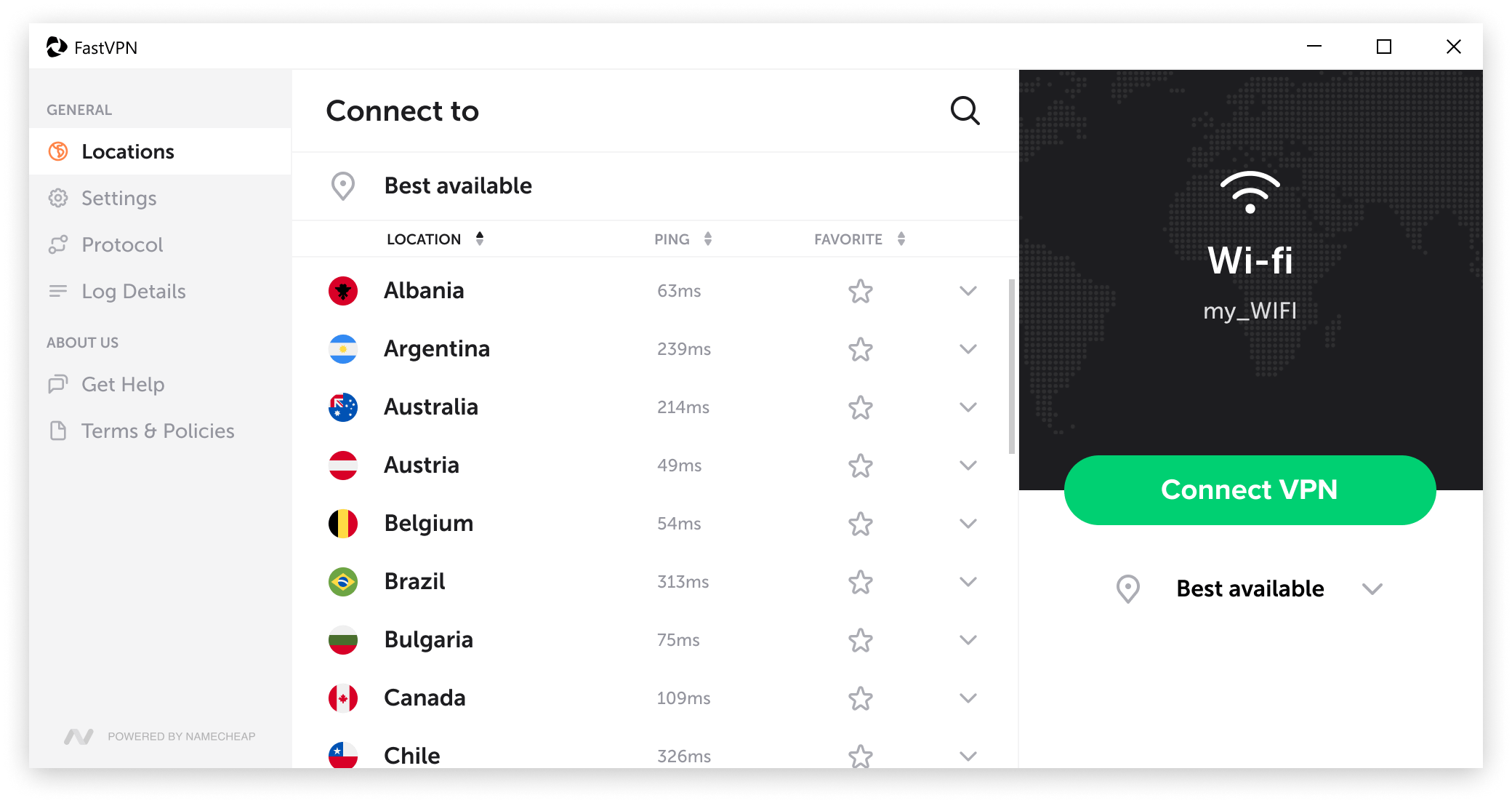
Explore the world with us
Choose from over 1000+ servers in 75+ locations
Discover the benefits of FastVPN
Secure all your devices so that you can work, stream, shop, and browse the internet anonymously without limitations.





Frequently asked questions
View more